服务器Ubuntu22.04系统下Ollama的
详细部署安装和搭配open_webui使用
详细部署安装和搭配open_webui使用
欢迎使用我们公司服务器来部署和使用Ollama大模型。通过本指南,您将学会如何在Ubuntu 22.04系统下安装和配置Ollama大模型,并使用open-webui进行交互。如果您对我们的服务器感兴趣,可以在官网处获取服务器资源,我们还提供详细的部署帮助文档,帮助您轻松上手。
Ollama介绍
Ollama 是一个开源的大模型管理工具,提供丰富的功能,包括模型的训练、部署、监控等。通过Ollama,你可以轻松地管理本地的大模型,提高模型的训练速度和部署效率。此外,Ollama还支持多种机器学习框架,如TensorFlow、PyTorch等,使你可以根据需求选择合适的框架进行模型训练。接下来,我们进入部署环节。
项目地址:https://github.com/ollama/ollama
部署框架
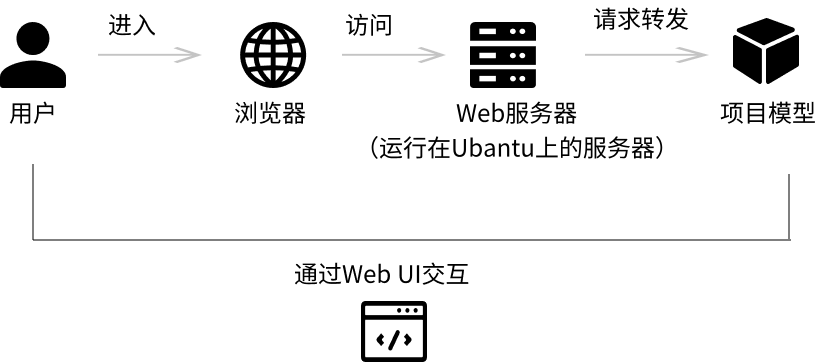 在这个框架中,每个组件都有其特定的角色和功能,它们通过Web UI这个桥梁相互连接,共同为用户提供服务。用户通过浏览器与Web服务器交互,而Web服务器则负责与后端的Ollama模型进行通信,以完成文字生成的任务。
在这个框架中,每个组件都有其特定的角色和功能,它们通过Web UI这个桥梁相互连接,共同为用户提供服务。用户通过浏览器与Web服务器交互,而Web服务器则负责与后端的Ollama模型进行通信,以完成文字生成的任务。 • 用户(User):
用户是最终与系统交互的人,他们使用Web UI来生成长对话。
• 浏览器(Browser):
用户通过浏览器访问Web服务器。浏览器充当客户端,发送HTTP请求并接收响应。
• Web服务器(Web Server):
运行在Ubuntu服务器上的软件,通常是Web框架的一部分,比如Flask或Django。它处理来自浏览器的HTTP请求,提供Web UI,并与后端服务交互。
• Ollama模型(Ollama Model):
Ollama是月之暗面科技有限公司开发的AI助手,擅长中英文对话,能处理长文本和多种文件,提供安全、合规的智能服务。
• Web UI(Web User Interface):
用户通过Web UI与系统交互。Web UI是Web服务器提供的前端界面,允许用户上传文字、设置生成参数等。
Ollama模型的优点和缺点
ollama 模型具有以下一些优点和缺点:
• 优点:
灵活性:可以在本地运行,用户对数据和使用环境有更大的控制权,适合对数据隐私有较高要求的场景。
可定制性:能够根据特定的需求和任务进行一定程度的定制和优化。
低依赖网络:在本地运行减少了对网络连接的依赖,保证在网络不稳定的情况下也能使用。
• 缺点:
资源需求:在本地运行可能需要较高的计算资源,包括硬件配置和内存等。
模型更新:与云服务相比,模型的更新可能不够及时和便捷。
初始设置复杂:对于非技术用户,本地部署和配置可能具有一定的难度。
性能上限:可能在某些复杂任务上的表现不如大规模云服务提供商训练的模型。
灵活性:可以在本地运行,用户对数据和使用环境有更大的控制权,适合对数据隐私有较高要求的场景。
可定制性:能够根据特定的需求和任务进行一定程度的定制和优化。
低依赖网络:在本地运行减少了对网络连接的依赖,保证在网络不稳定的情况下也能使用。
• 缺点:
资源需求:在本地运行可能需要较高的计算资源,包括硬件配置和内存等。
模型更新:与云服务相比,模型的更新可能不够及时和便捷。
初始设置复杂:对于非技术用户,本地部署和配置可能具有一定的难度。
性能上限:可能在某些复杂任务上的表现不如大规模云服务提供商训练的模型。
部署流程解释介绍
1. 购买 GPU 服务器
• 在官网购买并配置服务器:
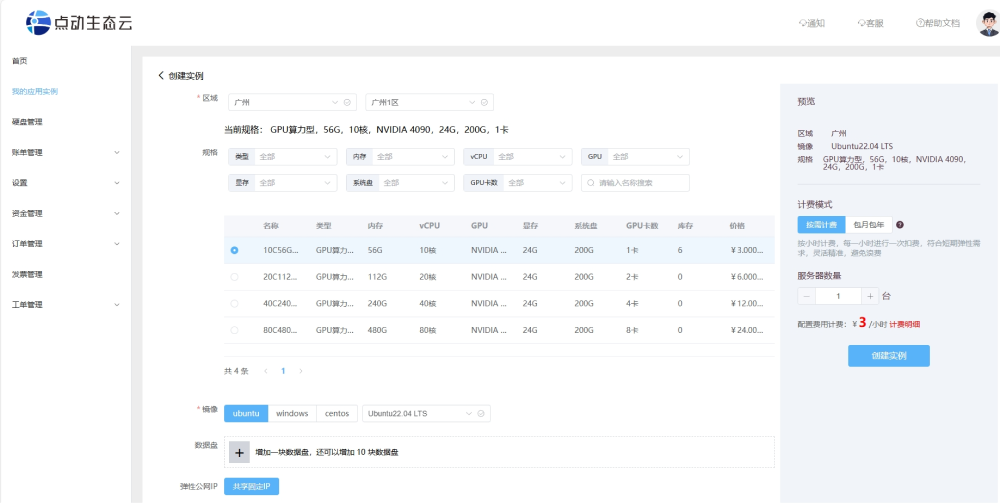 • 操作系统选择:
• 操作系统选择:
选择一个适合您需求的操作系统,通常推荐使用 Ubuntu 22.04 LTS,因为它提供了长期支持和稳定性。
• 购买和部署:
完成购买流程,启动服务器,并进行初步配置。
FinalShell是一款服务器管理工具,支持SSH和远程桌面,使用FinalShell远程连接配置服务器。
二、Ubuntu 22.04基本环境配置
• 更新包列表
确保系统获取到最新的可用软件包信息,以便能够安装最新或合适的版本。
• 安装 docker 依赖
用于验证 Docker 软件源的合法性和安全性。
• 添加阿里云 docker 软件源
为了提高下载速度或获取特定的优化配置。
• 安装 docker
Docker是一个容器化平台,它允许您在隔离的环境中运行应用程序。在系统中安装 Docker 引擎,以便能够使用 Docker 相关功能。
• 安装完成 docker 测试
验证 Docker 是否正确安装并且能够正常工作。
• docker 配置国内镜像源
加速 Docker 镜像的下载速度,减少因网络原因导致的下载缓慢或失败。
三、 安装英伟达显卡驱动
• 使用 Apt 安装
通过 Ubuntu 的包管理工具 Apt 来获取和安装适合系统的英伟达显卡驱动,使显卡能够正常工作并发挥最佳性能。
四、使用 docker 安装 ollama
• 使用 docker 拉取 ollama 镜像
从 Docker 仓库获取 ollama 的镜像,为后续运行容器做准备。
• 使用 docker 运行以下命令来启动 Ollama 容器
创建并启动一个基于 ollama 镜像的容器,使其能够运行。
• 使用 ollama 下载模型
获取所需的模型,以便 ollama 能够基于这些模型提供相应的服务。
五、使用 docker 安装 open-webui
• docker 部署 ollama web ui
通过 Docker 来搭建 ollama 的 Web 用户界面。
• 注册账号并成功进入:聊天界面
用户可以通过该界面与 ollama 进行交互和获取服务。
部署流程概述
• 环境配置:对 Ubuntu 和 Docker 进行基本环境配置,包括更新包列表、安装依赖、添加密钥和软件源来安装 Docker 并进行测试,还配置了国内镜
像源以优化 Docker 镜像的获取。
• 安装显卡驱动:通过 Apt 安装英伟达显卡驱动,为需要显卡支持的应用提供保障。
• 安装 open-webui:使用 Docker 安装 open-webui ,包括部署界面、注册账号,最终成功进入聊天界面以进行交互操作。
• 在官网购买并配置服务器:
• 操作系统选择:选择一个适合您需求的操作系统,通常推荐使用 Ubuntu 22.04 LTS,因为它提供了长期支持和稳定性。
• 购买和部署:
完成购买流程,启动服务器,并进行初步配置。
FinalShell是一款服务器管理工具,支持SSH和远程桌面,使用FinalShell远程连接配置服务器。
二、Ubuntu 22.04基本环境配置
• 更新包列表
确保系统获取到最新的可用软件包信息,以便能够安装最新或合适的版本。
• 安装 docker 依赖
用于验证 Docker 软件源的合法性和安全性。
• 添加阿里云 docker 软件源
为了提高下载速度或获取特定的优化配置。
• 安装 docker
Docker是一个容器化平台,它允许您在隔离的环境中运行应用程序。在系统中安装 Docker 引擎,以便能够使用 Docker 相关功能。
• 安装完成 docker 测试
验证 Docker 是否正确安装并且能够正常工作。
• docker 配置国内镜像源
加速 Docker 镜像的下载速度,减少因网络原因导致的下载缓慢或失败。
三、 安装英伟达显卡驱动
• 使用 Apt 安装
通过 Ubuntu 的包管理工具 Apt 来获取和安装适合系统的英伟达显卡驱动,使显卡能够正常工作并发挥最佳性能。
四、使用 docker 安装 ollama
• 使用 docker 拉取 ollama 镜像
从 Docker 仓库获取 ollama 的镜像,为后续运行容器做准备。
• 使用 docker 运行以下命令来启动 Ollama 容器
创建并启动一个基于 ollama 镜像的容器,使其能够运行。
• 使用 ollama 下载模型
获取所需的模型,以便 ollama 能够基于这些模型提供相应的服务。
五、使用 docker 安装 open-webui
• docker 部署 ollama web ui
通过 Docker 来搭建 ollama 的 Web 用户界面。
• 注册账号并成功进入:聊天界面
用户可以通过该界面与 ollama 进行交互和获取服务。
部署流程概述
• 环境配置:对 Ubuntu 和 Docker 进行基本环境配置,包括更新包列表、安装依赖、添加密钥和软件源来安装 Docker 并进行测试,还配置了国内镜
像源以优化 Docker 镜像的获取。
• 安装显卡驱动:通过 Apt 安装英伟达显卡驱动,为需要显卡支持的应用提供保障。
• 安装 open-webui:使用 Docker 安装 open-webui ,包括部署界面、注册账号,最终成功进入聊天界面以进行交互操作。
部署具体流程
一、FinalShell的下载及使用:
FinalShell是一款服务器管理工具,支持SSH和远程桌面,提供多标签管理、命令自动提示、SFTP、性能监控等功能,适用于开发运维,界面友好,在很大程度上可以免费替代XShell。
FinalShell的下载:https://www.hostbuf.com/t/988.html
FinalShell的基本使用:
连接Linux服务器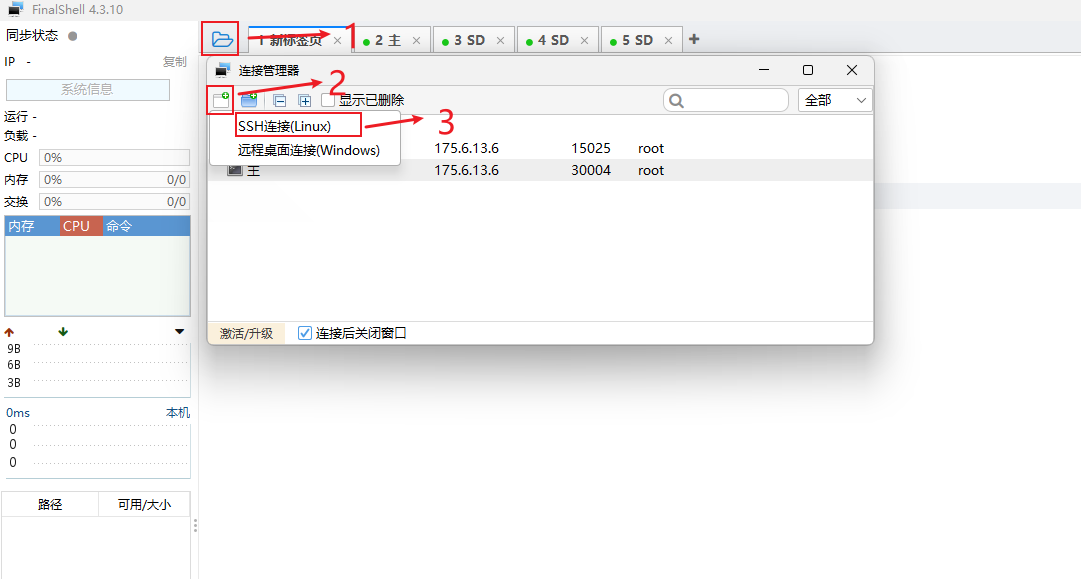 进行如下设置:
进行如下设置:
名称: 自定义
主机: 填写你的服务器的公网IP
端口: 填写服务器端口
备注: 自定义
方法: 密码
用户名:默认是root
密码: 填写服务器的登录密码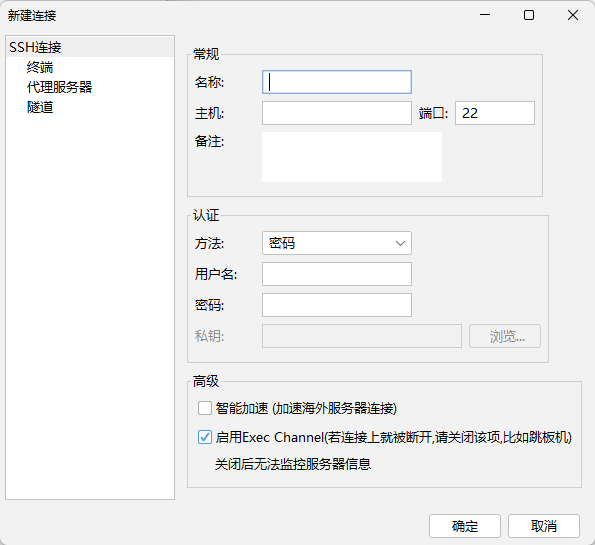 新建完后双击或者右键点击连接
新建完后双击或者右键点击连接
二、ubuntu22.04基本环境配置
1. 更新包列表
•打开终端,输入以下命令
更新时间较长,请耐心等待
 这里一直按enter键即可
这里一直按enter键即可  按enter键即可
按enter键即可
2. 安装docker依赖
3.添加阿里云docker软件源
 按enter键即可
按enter键即可
4.添加阿里云docker软件源
5.安装docker
 输入y允许安装
输入y允许安装  这里耐心等待即可
这里耐心等待即可  按enter键即可
按enter键即可 
6.安装完成docker测试

7.docker配置国内镜像源
7.1 编辑配置文件
按i进入编辑模式
加入以下内容: 按ESC键退出编辑模式,接着输入:wq,保存并退出
7.2 重新加载docker
7.3 重启docker
三、安装英伟达显卡驱动
使用 Apt 安装
• 配置存储库
• 更新包列表
• 安装 NVIDIA Container Toolkit 软件包
 这里也会比较久,请耐心等待,按enter键即可
这里也会比较久,请耐心等待,按enter键即可  按enter键即可
按enter键即可 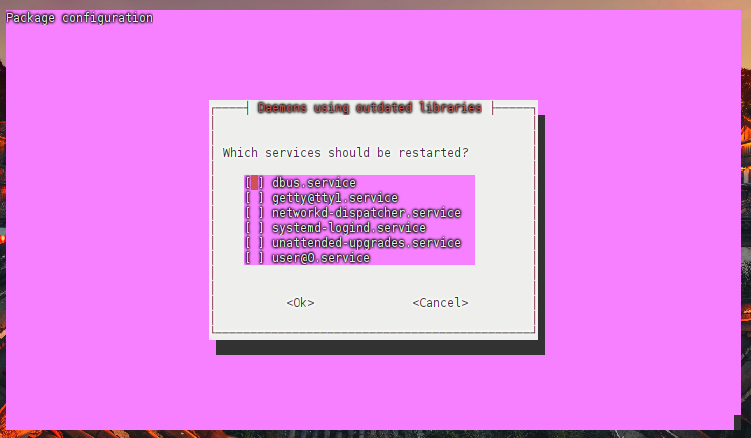
• 配置 Docker 以使用 Nvidia 驱动程序

• 重新启动docker
四、使用docker安装ollama
1.使用docker拉取ollama镜像
或使用国内镜像(推荐使用)
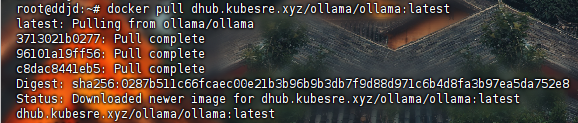 2.使用docker运行以下命令来启动 Ollama 容器
2.使用docker运行以下命令来启动 Ollama 容器
使ollama保持模型加载在内存(显存)中
• 参考文章
ollama如何保持模型加载在内存(显存)中或立即卸载
• 执行以下命令:
3.使用ollama下载模型
• 这里示例下载阿里的通义千问
运行效果如图: 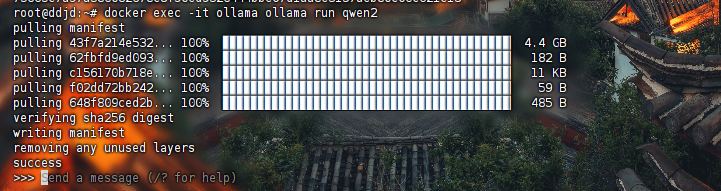 下载成功
下载成功
ctrl+D退出聊天
• 模型库
五、使用docker安装open-webui
1.docker部署ollama web ui
查看自己服务器的业务端口,我们这里是30131-30140
如下方打开购买服务器端口映射信息,这里的业务端口可以设置30131到30140之间的端口号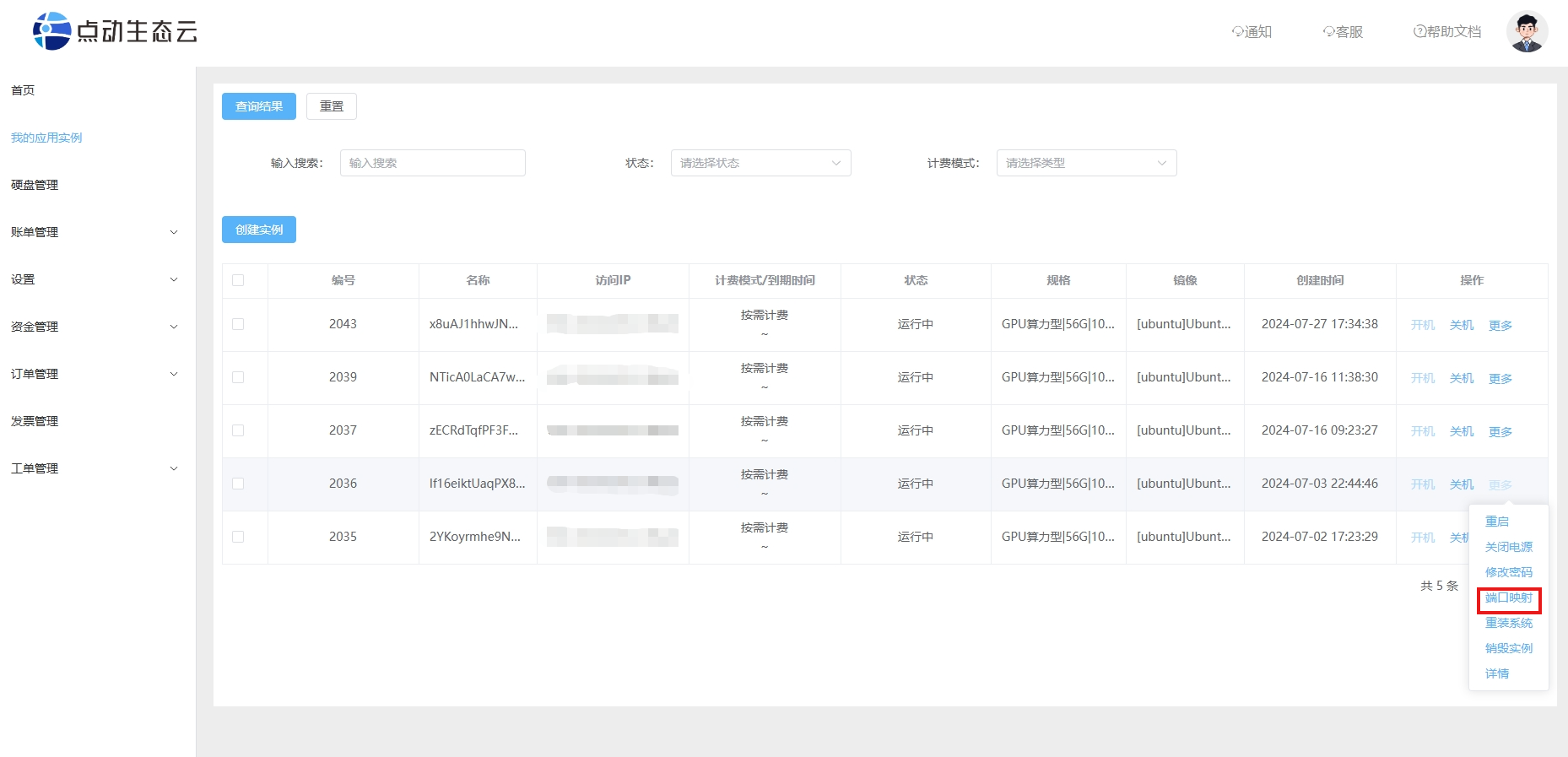
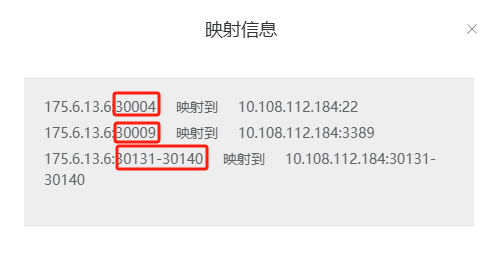 • 映射信息解释:
• 映射信息解释:
1.Linux(Ubuntu/CentOS)类操作系统连接内网22端口
2.Windows操作系统连接内网3389端口
3.业务端口
• main版本• cuda版本
• 安装成功后,可以在另一台计算机进行访问,如下: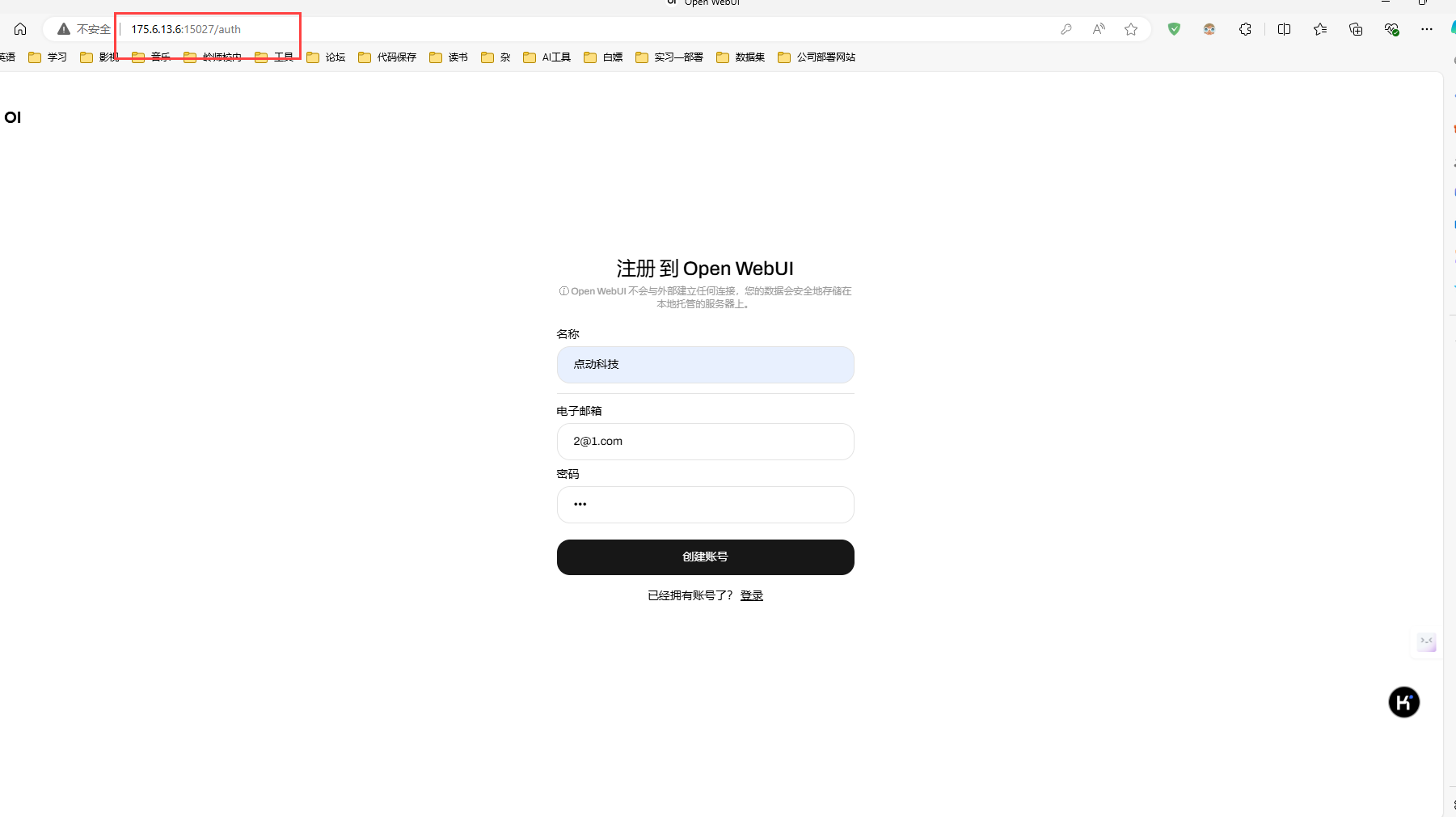
2.注册账号
默认第一个账号是管理员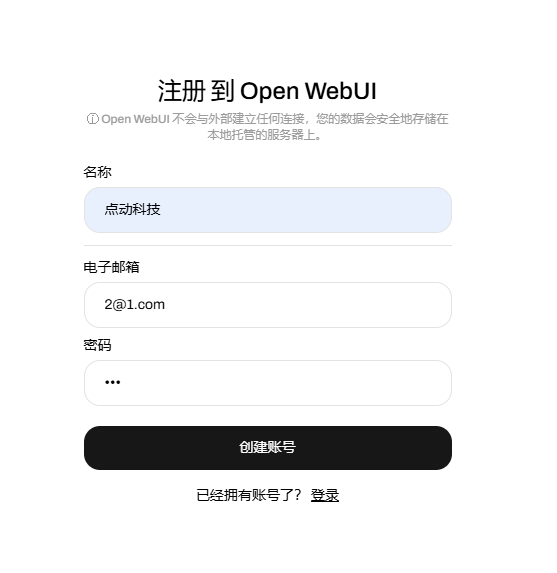
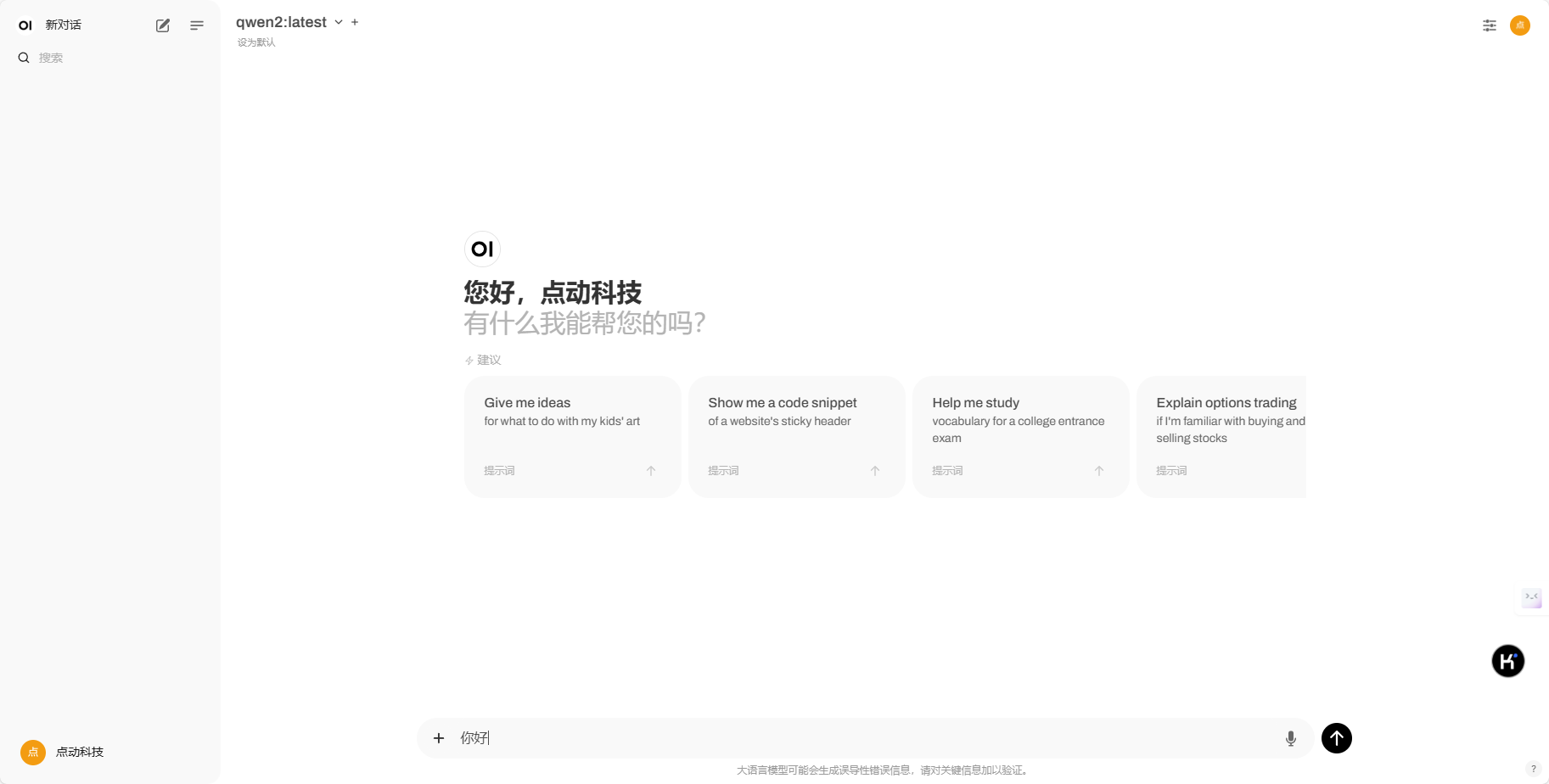
3.成功进入聊天界面
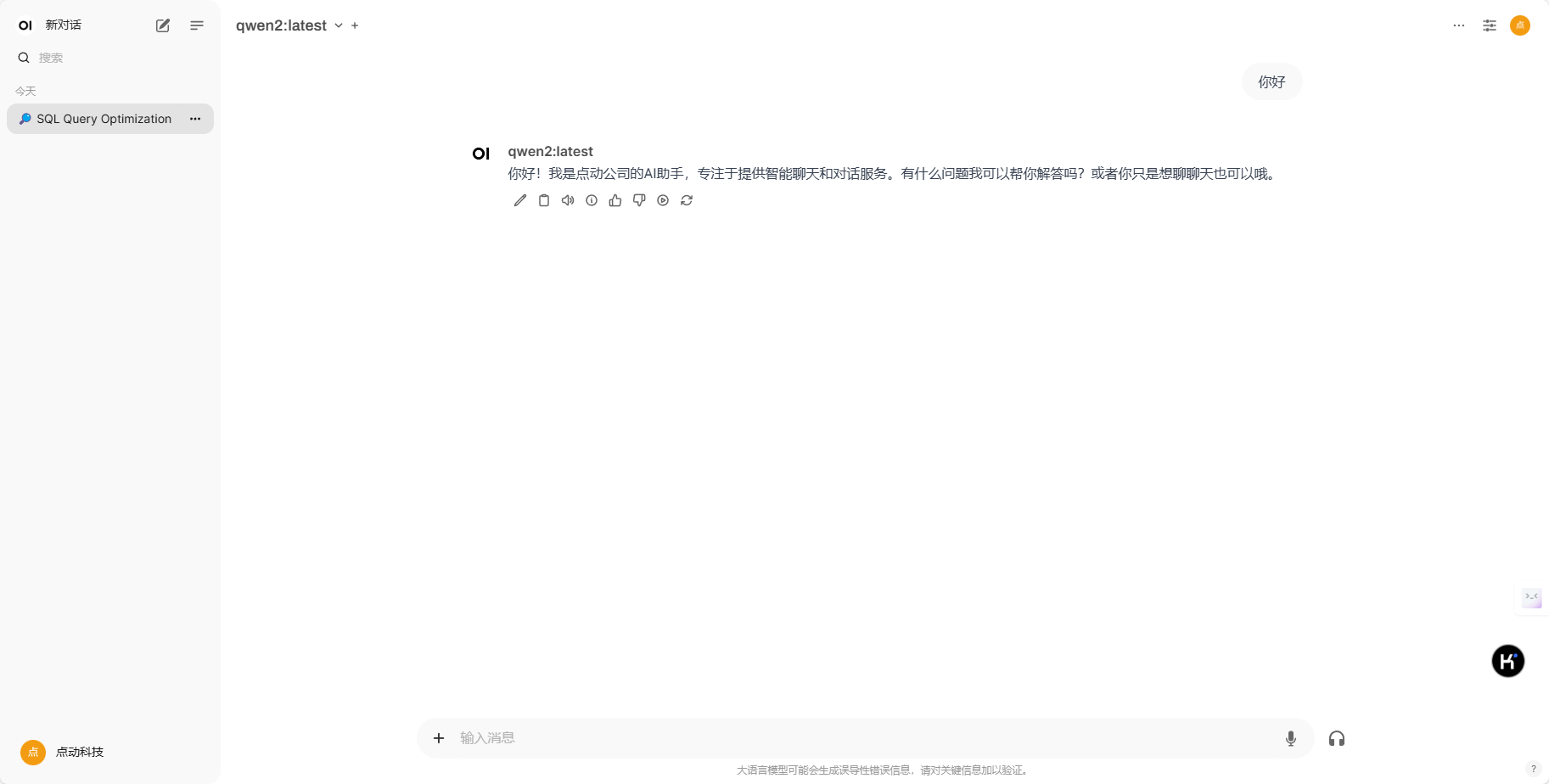
4.成功安装
FinalShell是一款服务器管理工具,支持SSH和远程桌面,提供多标签管理、命令自动提示、SFTP、性能监控等功能,适用于开发运维,界面友好,在很大程度上可以免费替代XShell。
FinalShell的下载:https://www.hostbuf.com/t/988.html
FinalShell的基本使用:
连接Linux服务器
进行如下设置:名称: 自定义
主机: 填写你的服务器的公网IP
端口: 填写服务器端口
备注: 自定义
方法: 密码
用户名:默认是root
密码: 填写服务器的登录密码
新建完后双击或者右键点击连接二、ubuntu22.04基本环境配置
1. 更新包列表
•打开终端,输入以下命令
sudo apt-get update
sudo apt upgrade更新时间较长,请耐心等待
这里一直按enter键即可 按enter键即可2. 安装docker依赖
sudo apt-get install ca-certificates curl gnupg lsb-release3.添加阿里云docker软件源
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -4.添加阿里云docker软件源
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"5.安装docker
apt-get install docker-ce docker-ce-cli containerd.i6.安装完成docker测试
docker -v7.docker配置国内镜像源
7.1 编辑配置文件
vi /etc/docker/daemon.json加入以下内容:
{
"registry-mirrors":
[
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://docker.m.daocloud.io",
"https://ghcr.io",
"https://mirror.baidubce.com",
"https://docker.nju.edu.cn"
]
}7.2 重新加载docker
sudo systemctl daemon-reload7.3 重启docker
sudo systemctl restart docker三、安装英伟达显卡驱动
使用 Apt 安装
• 配置存储库
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey \
| sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list \
| sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' \
| sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list• 更新包列表
sudo apt-get update• 安装 NVIDIA Container Toolkit 软件包
sudo apt-get install -y nvidia-container-toolkit• 配置 Docker 以使用 Nvidia 驱动程序
sudo nvidia-ctk runtime configure --runtime=docker• 重新启动docker
sudo systemctl restart docker四、使用docker安装ollama
1.使用docker拉取ollama镜像
docker pull ollama/ollama:latestdocker pull dhub.kubesre.xyz/ollama/ollama:latestdocker run -d --gpus=all --restart=always -v /root/project/docker/ollama:/root/project/.ollama -p 11434:11434 --name ollama ollama/ollama• 参考文章
ollama如何保持模型加载在内存(显存)中或立即卸载
• 执行以下命令:
docker run -d --gpus=all -e OLLAMA_KEEP_ALIVE=-1 -v /root/docker/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama3.使用ollama下载模型
• 这里示例下载阿里的通义千问
docker exec -it ollama ollama run qwen2ctrl+D退出聊天
• 模型库
| 模型 | 参数数量 | 大小 | 下载方式 |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | docker exec -it ollama ollama run llama2 |
| Mistral | 7B | 4.1GB | docker exec -it ollama ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | docker exec -it ollama ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | docker exec -it ollama ollama run phi |
| Neural Chat | 7B | 4.1GB | docker exec -it ollama ollama run neural-chat |
| Starling | 7B | 4.1GB | docker exec -it ollama ollama run starling-lm |
| Code Llama | 7B | 3.8GB | docker exec -it ollama ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | docker exec -it ollama ollama run llama2-uncensored |
| Llama 2 | 13B | 7.3GB | docker exec -it ollama ollama run llama2:13b |
| Llama 2 | 70B | 39GB | docker exec -it ollama ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | docker exec -it ollama ollama run orca-mini |
| Vicuna | 7B | 3.8GB | docker exec -it ollama ollama run vicuna |
| LLaVA | 7B | 4.5GB | docker exec -it ollama ollama run llava |
| Gemma | 2B | 1.4GB | docker exec -it ollama ollama run gemma:2b |
| Gemma | 7B | 4.8GB | docker exec -it ollama ollama run gemma:7b |
五、使用docker安装open-webui
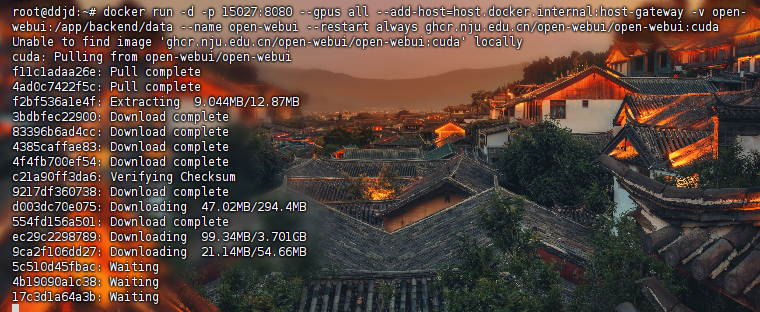
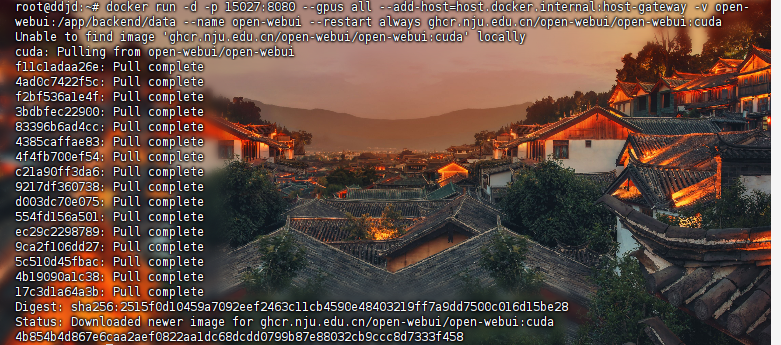
1.docker部署ollama web ui
查看自己服务器的业务端口,我们这里是30131-30140
如下方打开购买服务器端口映射信息,这里的业务端口可以设置30131到30140之间的端口号
• 映射信息解释:1.Linux(Ubuntu/CentOS)类操作系统连接内网22端口
2.Windows操作系统连接内网3389端口
3.业务端口
• main版本
docker run -d -p 15027:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:maindocker run -d -p 15027:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:cuda• 安装成功后,可以在另一台计算机进行访问,如下:
2.注册账号
默认第一个账号是管理员
3.成功进入聊天界面
4.成功安装